This is a project that I lead and is supported by about JOD31,000 by the Jordanian Scientific Research and Innovation Support Fund.
Project Summary
Many Arabic speakers have difficulties expressing in formal Arabic. The reasons for these difficulties are numerous, the most important of which is that the vernacular languages in the Arab countries are informal Arabic dialects that differ to varying degrees from the formal language. Weakness in the formal Arabic language leads to writing weak Arabic texts that are full of written, lexical, morphological, grammatical, and syntactic errors, or to abandoning the use of the formal language and resorting to writing in the informal dialect or in foreign languages such as English and French.
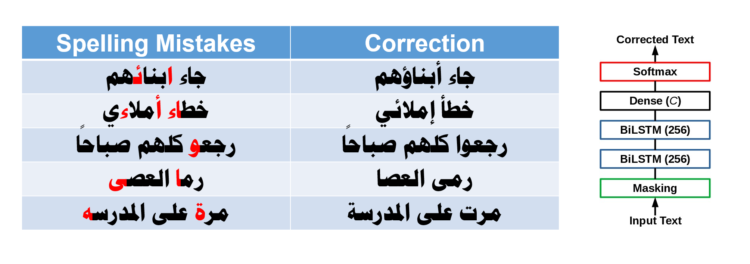
This project aims to develop computer applications and make them available to Arabic speakers in Jordan to enable them to correct the Arabic texts they enter through their computers and mobile phones and to convert them from texts in the informal Jordanian dialect or from texts with various linguistic errors into sound and fully diacritized Arabic texts. Providing these applications will have a great impact on facilitating communication among users of the Arabic language in Jordan, eliminating many communication and confusion errors, improving the language of communication, and improving the Arabic content on the internet. The use of these applications will also have a positive impact on improving the linguistic skills of users; when the user sees how these applications correct her or his linguistic errors in a timely manner.
This project also aims to provide scientific research contributions in providing datasets necessary for Arabic language research, in developing algorithms for processing natural languages and using machine learning techniques to correct various spelling and linguistic errors. We hope that the scientific outputs of this project will contribute to the advancement of computer support for the Arabic language in Jordan and the Arab world in general.
The main research question of this project is what deep machine learning models and training techniques are appropriate to efficiently correct Arabic language mistakes and to translate text in the Jordanian dialect to proper diacritized text in formal Arabic? The research methodology of this project is based on deep machine learning techniques, and this requires carrying out a broad and accurate process to collect sufficient samples of Arabic sentences from Jordanian users with different linguistic errors or in the local informal dialect, and then writing the correct linguistic text in standard Arabic against each sample. Because deep machine learning needs large number of samples that are not available and collecting them is expensive, machine learning processes in the project will be supported with synthetic samples as well as employing transfer learning methods to develop machine learning solutions that rely on these samples to translate the input text into valid and diacritized text. The research also includes developing Internet and smartphone applications in which the developed solutions are embedded to be provided to the Jordanian user.